
投稿来源:脑极体
在工业界的热情参与下,AI行业大会近年来的发展可谓是如火如荼。不过,依然很少有哪个能比得上CVPR在计算机视觉领域的影响力。其中, 又以oral口头报道的文章最具重量级。
那么在CVPR 2019中,又有哪些成果获此殊荣呢?
伯克利大学研究小组提出的Open Long-Tailed Recognition (OLTR)开放长尾识别,就为计算机视觉系统在现实世界中的应用提供了新的分类标准。
以往的CV系统存在哪些问题,OLTR又提供了哪些解决方案?不妨通过一篇文章抢先了解一下。
实验室与现实的距离:神经网络的“视觉盲点”
长久以来,我们理解中的机器视觉往往是这样工作的:
研究人员会依据图像所具有的本身特征先将其分类,然后设计一个算法,使用设定好的数据集进行预训练。然后,给AI一张图片,它会根据存储记忆中已经分好的类别进行识别,查看是否有与该图像具有相同或类似特征的存储记忆,从而快速识别出是该图像。只要投喂足够多的照片,特征分类足够准确,识别算法的精准度也会逐步提升。
模式识别技术近两年突飞猛进,加上在公共安全、工业、农业、交通、生物等领域的不断落地,比如车牌识别、人脸识别、指纹识别、心电图检测等等,是应用最为成熟、群众基础最为广泛的AI技术之一。
但,问题也出在这里。
由于训练数据和测试数据都是在封闭环境下进行的,比如ImageNet数据集,这与现实世界中的情况却截然不同。
因为在现实中,充斥着许多无法出现在测试数据集中的开放类别。它们要么数量珍贵而稀少,比如自然界中的野生动物;要么繁多而不规律,诸如街道标志、时尚品牌、面孔、天气状况、街道状况等等,在日常生活分布的概率也是不平衡的。
如果只是简单地将现有的计算机视觉分类放在现实中的识别问题上,结果会怎样呢?伯克利的研究人员告诉你,就是被打脸。

(现有的计算机视觉分类与现实世界的场景之间存在相当大的差距)
当以为生态学家想利用现有的CV技术来识别相机中所捕捉到的野生动物时,不出意外地,由于没有足够的训练数据,系统失败了……
更令人悲伤的是,在此类情境中,收集更多数据是非常不现实的。
对于一些濒临灭绝的野生珍稀动物,人们往往要花很长的时间,甚至要等上好几年才能成功拍到一次照片。与此同时,新的动物物种不断出现,旧的动物物种不断离开。在自然界这个动态系统中,识别对象的总分类数从来没有固定过。
即使现有的计算机视觉技术在大众类别上做得再好,比如精准识别出人类和猫狗等,但对于这些不均衡的分类对象,现在的方法依然无能为力。

之所以出现这种问题,核心原因或在于:面对实际应用时,机器视觉的分类任务不应该被作为单项任务来对待并解决,而应该当成一个整体来看待。即一个能够对少数拥有海量ImageNet数据集的常见类别,以及大多数罕见类别,都能够进行分类的实用系统。
要实现这一点,就要求CV系统具备一种能力,能够从几个已知的事例中推导出单一类别的概念,并对一个从未见过的类别的实际图例对应上新的概念。这就不再是逻辑命题,而是智慧型的学习命题了。为了尽可能地消灭“次元壁”中存在的“视觉盲点”,OLTR开放长尾识别框架应运而生。
OLTR,让CV系统更全能
如上所述,“开放长尾识别”(OLTR)的核心任务目标,就是让系统能够从长尾数据和开放的分布式数据中进行学习,能够在包括头、尾和开放类的平衡测试集上表现出较好的分类精度。
也就是说,除了一些主流的样本丰富的对象,对于数据匮乏的、分布广泛导致出现频率不均衡的物体,系统也能够做到很好的识别。
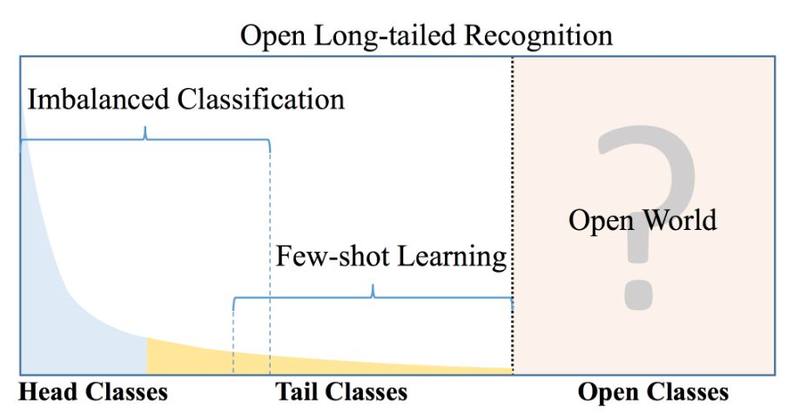
显然,有了OLTR的机器视觉会变得能力更全面,也更符合现实环境的需求。它的特殊之处,主要依靠视觉记忆能力来实现。
研究人员将图像映射到一个特征空间,将图像特征和记忆特征结合在一起,这样视觉系统就可以基于封闭环境分类的学习度量,对开放世界中存在的新颖物体和长尾类进行理解。即使在缺乏观察数据和特征的情况下,视觉记忆也能够对开放类进行理解并努力识别。
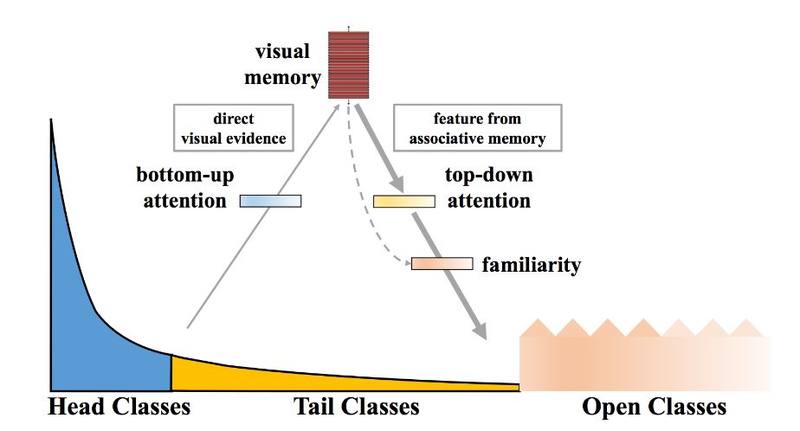
(让CV系统具备视觉记忆能力)
实验结果显示,记忆特征的加入,使得CV系统能够更好地激活起视觉神经元。比如,识别“公鸡”这一长尾类物体(位于下图左上角cock)时,具有记忆功能的CV系统已经学会了将其转换为“鸟头”、“圆型”和“虚线纹理”的视觉概念,并将被普通CV模型错误分类的图片正确地识别了出来。


(从内存特性中注入视觉记忆特征的系统示例)
在现实任务中,这种新方法也表现出了极强的开放性,能够在不牺牲丰富类的前提下,对稀缺类别的识别实现明显的改进。
以前面提到的认识野生动物为例,对于那些图像不超过40幅的种类,OLTR实现了从25%到66%的性能提升。
与目前大多数计算机视觉方案相比,OLTR显然更符合数据自然分布的真实世界。那么,它的出现最有可能给哪些CV技术带来改变呢?
检测、分割:CV问题的新解法
可以明确的是,OLTR的出现,解决了CV领域最为经典的问题之一——分类(classification)。那么,自然也就间接影响了分类问题的诸多应用领域。其中,比较多的就是目标检测和图像分割。
先说说目标检测。
目标检测已经在诸多产业中都有应用,简单的论文也越来越难发表了,比如手机拍照中用一个框来定位人脸,或者是智能监控中的人体定位,都属于目标检测的范畴。
但关于它的技术探索还远没有达到劝退科学家的程度,这是因为,目标检测算法目前还存在着不少亟待突破的难点:
比如数据标注的巨大成本,能不能通过更有小弟分类来解决;小规模数据的监督学习怎样才能更有效地提升精度;对单图像单类别场景进行弱监督多类检测学习等等。
这些都是应用场景中比较需要关注的问题,恰好也是OLTR能够带来改变的地方。

再说图像分割。简单来说就说输入一张图片,然后对每一个像素点都进行分类标记,则完成了对整个图片的分割。
比如深度学习对医学影像进行解读和诊断,自动驾驶汽车区分人、车、障碍物等,就采用了语义分割的技术。
但该类算法目前面临着三大难题:一是计算成本高,要保证准确率,需要的存储空间和数据都非常庞大。二是计算效率低,由于需要对每个像素块进行计算卷积,造成了很大程度的重复和算力浪费;三是性能桎梏,受像素块的限制,感知神经元往往只能提取一些局部特征,从而影响分类识别的准确率。
节约计算量、尽可能考虑全局信息、高性能分类,是图像分割未来迭代的重点。

此时,OLTR的优势就展现出来了。
首先,它用增强视觉记忆的方式,帮助CV系统在头部类别的基础上完成尾部、开放类别的特征分类与学习,这意味着可以告别超大规模的数据集,通过小样本的无监督学习一样能够达到同样的高精度性能,降低了计算机视觉的应用和训练成本。
其次,由于OLTR具有通用化、整体性的分类能力,使得CV系统能够在现实环境中表现的更好,尤其是面对一些出现频率低、难以进行监督训练的物体时,系统能够根据以往的“经验”为其赋予新的视觉概念并识别出来。对于性能要求极高的自动驾驶、医疗诊断等应用来说,无疑是雪中送炭。
总而言之,OLTR的出现,将给CV算法、软件与产业应用都带来不小的改变。但其势能有多大,还需要有越来越多的开发者和企业开始尝试用其解决现实问题,逐步迭代升级,后续想必还会有不少惊喜。
即使是习以为常的技术,也有自我思考和蝶变的可能。身处时代变革中心的我们,不妨共同期待一下CPVR 2019还有哪些创造。